
Tuesday, September 24, 2013
Thursday, September 5, 2013
Oh, Facebook; you're so smart!

The machines are getting smarter...
It would be a source of comfort to say these guys don't know what they're doing, or to point out that their somewhat unflattering raft of interface problems stemming from beleaguered continuous integration back in 2011 clearly indicate this sort of thing is just a technical malfunction.
No, I'm afraid it's not so happenstance. I submit that this is a process for similarity assessment that sees through what the intimidated citizen is not so comfortable seeing - an algorithm more sagacious and penetrating than it's handlers might be comfortable with.
Monday, August 26, 2013
Amazon Accidental?
The more you look, the worse it gets. Amazon can fairly be described as a gigantic internet corporation and the father of popular cloud computing, used universally by startups and established businesses alike for provisioning of virtualized data, processing, and storage. It's flamboyant figurehead, Jeff Bezos, is so pleased with the capabilities and infallibility of Amazon that he has formed a privately held company to strike out into space.
So why is it that this juggernaut of perfection, scale, and engineering can't do a percentage or summarize a three-item list? Would you get into a vehicle whose celestial navigation systems have been engineered by a company that has trouble sorting a list of three?
I went searching for a Kindle today and found that outside of Amazon, on eBay for example, pickings are surprisingly slim. So on Amazon's website, I did a search for Kindles and within a mere 10.767s (!?) it returned some items. The first that meets my needs is a Kindle 'Paperwhite' device - Amazon showing me that there are three available for as little as $54.99 used. Good enough, I say! Let's get on with it then.
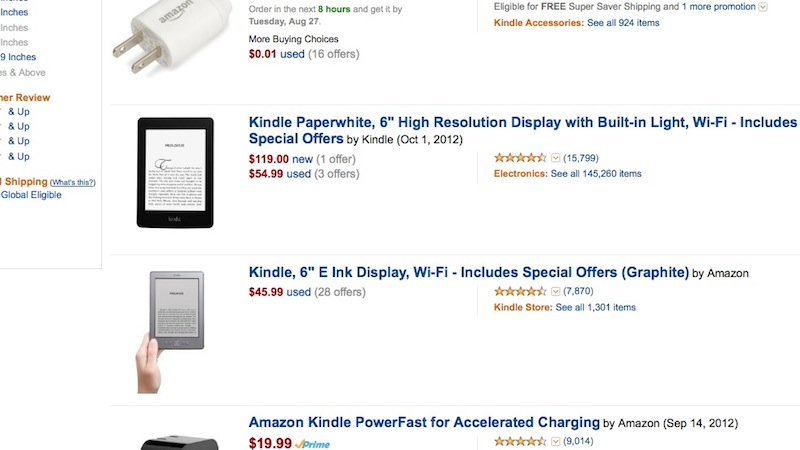
Clicking on the link (the word 'used' adjacent to the advertised $54.99 price in this case) takes me to another page with a short product description and availability displayed below as tabs. The puzzling thing is that the 'tab' currently highlighted optimistically announces "Used from $54.99 (Save 53%), yet the first item displayed from this list of three, sorting in ascending price order is $139.99, not including shipping.
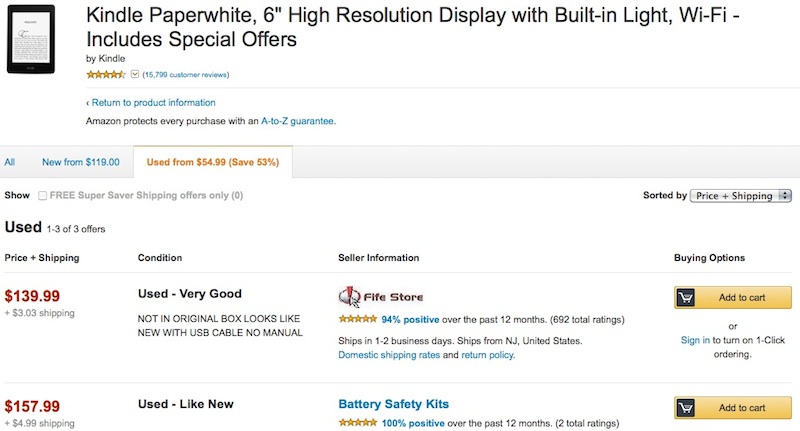
Now, I hesitate to use the phrase It's not rocket-science, so I got to thinking about alternatives for this awfully sloppy and disorienting user-experience. The way I see it, there are four distinct possibilities here, and none flatter the implementers, unfortunately, but at least they provide some range of options to assign points of failure in their implementation:
No - it really looks as if the bait-and-switch presentation is the most likely explanation, which means once you're in one of those fancy Amazon rocket-ships to Mars you may find that the ticket price did not include oxygen for the trip, or worse, the navigational computations for the trip will routinely have 'accidental' errors in the neighborhood, optimistically, of 55.93/54.99... Curiously, the shortest distance between the earth and Mars is about 54.6M kilometers, so the spaceship might drop you off about 600,000 miles shy of Mars. Better hold your breath! In either case, not very confidence-inspiring.
So why is it that this juggernaut of perfection, scale, and engineering can't do a percentage or summarize a three-item list? Would you get into a vehicle whose celestial navigation systems have been engineered by a company that has trouble sorting a list of three?
I went searching for a Kindle today and found that outside of Amazon, on eBay for example, pickings are surprisingly slim. So on Amazon's website, I did a search for Kindles and within a mere 10.767s (!?) it returned some items. The first that meets my needs is a Kindle 'Paperwhite' device - Amazon showing me that there are three available for as little as $54.99 used. Good enough, I say! Let's get on with it then.
Clicking on the link (the word 'used' adjacent to the advertised $54.99 price in this case) takes me to another page with a short product description and availability displayed below as tabs. The puzzling thing is that the 'tab' currently highlighted optimistically announces "Used from $54.99 (Save 53%), yet the first item displayed from this list of three, sorting in ascending price order is $139.99, not including shipping.
Now, I hesitate to use the phrase It's not rocket-science, so I got to thinking about alternatives for this awfully sloppy and disorienting user-experience. The way I see it, there are four distinct possibilities here, and none flatter the implementers, unfortunately, but at least they provide some range of options to assign points of failure in their implementation:
- Bad batch management: the summary page - the gigantic array of hashes within hashes that represents search results, is decoupled from changing information, so that as stock is turned over, search results represent an older snapshot of stock than what is currently available. Sad.
- No snapshots: the search result representation of available stock is being generated continuously, such that the situation outlined above happens for small subsets of the data, but a single search can never range through an accurate representation of available stock/prices at a singular point in time. Likely, but does not explain the longevity of this inaccuracy (8 hours and counting as of Mon Aug 26 12:10:28 EDT 2013).
- Bubbling: the common practice of altering the markup or selectivity that targets me as opposed to you, or me on the first visit from me on the second visit. Google does this extensively with search results, and Amazon has to do it to some degree, but I don't think they are as sophisticated with it.
- Deliberate under-reporting of result price to suck you in, just in case you will decide the price must be rising fast, accept the higher than advertised price, not notice, or in any other way rationalize the bait-and-switch and click 'Buy' anyway.
No - it really looks as if the bait-and-switch presentation is the most likely explanation, which means once you're in one of those fancy Amazon rocket-ships to Mars you may find that the ticket price did not include oxygen for the trip, or worse, the navigational computations for the trip will routinely have 'accidental' errors in the neighborhood, optimistically, of 55.93/54.99... Curiously, the shortest distance between the earth and Mars is about 54.6M kilometers, so the spaceship might drop you off about 600,000 miles shy of Mars. Better hold your breath! In either case, not very confidence-inspiring.
Friday, June 28, 2013
The Bug that Surfaced while Blogging Another Bug - Quicktime
So I was blogging the LinkedIn bug I found today, and this happened. Oops, Apple!
LinkedIn comment editor bug.
Responding to a thread on LinkedIn today, I noticed an annoying bug in the resizeable text control. It's a movement bug, so I decided to make a video of it for your enjoyment.
Friday, May 31, 2013
On Apathy, Voting, and Scalability
Though I have mostly focused on web portal bugs here, this has led to a sort of apathy for a number of reasons.
First, there are too many bugs in web portals. If you look for them, there seems to be, on average, more than one bug per web-page on the internet. Some of these are common, glaring, and recurrent to the point that they become boring to find. Navigating them is a lot like communicating with someone who does not speak the language well and is not paying attention - you just deal with it while trying not to become too bogged down in the workarounds. Facebook interface problems alone could fill a blog with daily entries for several years.
I have also recently spent a good deal of time on latin-american sites, where QA seems to be an alien concept, navigation is atrocious, functionality is spotty at best, and information is tremendously unreliable. Critiquing these is a waste of time, because the list of what works correctly is generally shorter than the list of what does not. Web-construction tends to be superficially imitative and full of poorly-implemented bells & whistles, while basic navigation and visual organization are clearly mostly not understood. If you like computing, it's a bit soul-crushing.
So, in the interest of not stopping altogether, here is one I found some time back on YouTube. This is interesting because YouTube seems to be on a continual release cycle, and the number and quality of improvements Google has made to the property since the purchase is absolutely staggering. It seems that, without much of a splash, virtually every pixel on YouTube now is subtly changed and has slightly different and vastly improved code behind it, while the visual metaphor has been gently shifted.
So here's some random video with 5,348 likes and 15 dislikes after 1,448 total views... There you go: Bug du Jour. I'm sure it was fixed in no-time, and I bet it's related to scalability. Here's why:
Back in 2007, when I worked at CurrentTV, one of the early problems I faced had to do with voting that was falling on its face, showing the user a beach-ball/hourglass for 15s after the click, at a time when Current.com had about 500 real users. That's abysmal performance by any standard, but when you consider the deals Current TV had in place with vendors that had Oracle running on fully-loaded state-of-the-art servers, there's obviously an issue, right?
Well, this is not an unusual scenario. Functionality that develops dynamically pushes prototypes into production with time-to-market trumping architecture, and the belief that this can be fixed later at center-stage in most product and release-planning decisions. All true and reasonable. People, however, have a tendency to freak out at this juncture in a prototype's life, but that's another topic. The story here is that programmers had conceived of a voting system that showed a tally, and made the mistake of trying to get technical sign-off from non-technical stake-holders*1, which had resulted in an additional (and reasonable) requirement that the user's vote be reflected instantly in the displayed tally of votes. Naturally, the programmer who wrote this function sent the vote to the SQL server and ran a query asking for the count of upvotes. The trouble was that the indexes were wrong on the table, so the update query was pretty slow, and the transaction isolation level was set to repeatable read, causing the query to block the count query.
To solve the problem I made a transactional table with asset IDs & vote counts (actually I did collect user IDs, timestamps, & origin IPs for analytical & weighting reasons, but not relevant to the story), indexed on these columns separately, and made the code get the vote tally initially on load, use a read_uncommitted connection, send the vote update off on a separate thread, and instead of re-querying for the tally, simply increment the on-load tally by 1 locally.
Net effect: wait-time for voting at 500 users reduced from ~15s to ~240ms, database reads for votes reduced by a factor of 2, expected performance for 1,000,000,000 users: ~630ms*2
So a little planning and application of basic algebraic principles can make the difference between handling a billion users comfortably and reaching a performance limit at 500 users.No doubt, YouTube was in the middle of making a change somewhat along this vein to their voting algorithm when I stumbled onto this bizarre result. I have, in any case, been unable to reproduce it since.
*1 - One might ask why this is a mistake. The reason is that non-technical users don't usually have practice visualizing a complete site from specifications, or being aware of the interdependence between logically separate presentation elements unless specifically shown. What happens then is that when users are shown partial implementations, it sets their wheels turning about the functionality that will go on top of the current functionality, and without looking at the current spec, they will at worst fall into the trap of reinventing already-specified functionality, and at best think of brand new functionality to add, sometimes resulting in significantly increased scope, regressions, and project slippages.
*2 - The performance prediction is based on the number of seeks it requires to read a b-tree index. Updating or inserting a row in a database will require two additional seeks, so we can add 2 to the result, but what is of interest here is noting that this number can be computed pretty reliably using the formula:
log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1
since block-lengths are usually 1024 bytes, an index on a mediumint column is three bytes long, a data pointer able to hold 4G discrete values is 4 bytes, then for 500 rows:
log(500) / log(1024 / 3 * 2 / (3 + 4)) + 1 = ln(500)/ln(2048/21) + 1 = 2.35
-a write requires 2 additional seek requests. So if we take the complete operation on a 500 row table to require 6.7 seeks (2.35 for the original read and 4.35 for the update), then the same operation on a 1 billion row table will require ~7.8 seeks, and 9.8 for the update, for a total of 17.6.
If 6.7 seeks took ~240ms, 17.6 will take 17.6/6.7*240=630ms
QED
First, there are too many bugs in web portals. If you look for them, there seems to be, on average, more than one bug per web-page on the internet. Some of these are common, glaring, and recurrent to the point that they become boring to find. Navigating them is a lot like communicating with someone who does not speak the language well and is not paying attention - you just deal with it while trying not to become too bogged down in the workarounds. Facebook interface problems alone could fill a blog with daily entries for several years.
I have also recently spent a good deal of time on latin-american sites, where QA seems to be an alien concept, navigation is atrocious, functionality is spotty at best, and information is tremendously unreliable. Critiquing these is a waste of time, because the list of what works correctly is generally shorter than the list of what does not. Web-construction tends to be superficially imitative and full of poorly-implemented bells & whistles, while basic navigation and visual organization are clearly mostly not understood. If you like computing, it's a bit soul-crushing.
So, in the interest of not stopping altogether, here is one I found some time back on YouTube. This is interesting because YouTube seems to be on a continual release cycle, and the number and quality of improvements Google has made to the property since the purchase is absolutely staggering. It seems that, without much of a splash, virtually every pixel on YouTube now is subtly changed and has slightly different and vastly improved code behind it, while the visual metaphor has been gently shifted.
 | |
| What's wrong with this picture? |
Well, this is not an unusual scenario. Functionality that develops dynamically pushes prototypes into production with time-to-market trumping architecture, and the belief that this can be fixed later at center-stage in most product and release-planning decisions. All true and reasonable. People, however, have a tendency to freak out at this juncture in a prototype's life, but that's another topic. The story here is that programmers had conceived of a voting system that showed a tally, and made the mistake of trying to get technical sign-off from non-technical stake-holders*1, which had resulted in an additional (and reasonable) requirement that the user's vote be reflected instantly in the displayed tally of votes. Naturally, the programmer who wrote this function sent the vote to the SQL server and ran a query asking for the count of upvotes. The trouble was that the indexes were wrong on the table, so the update query was pretty slow, and the transaction isolation level was set to repeatable read, causing the query to block the count query.
To solve the problem I made a transactional table with asset IDs & vote counts (actually I did collect user IDs, timestamps, & origin IPs for analytical & weighting reasons, but not relevant to the story), indexed on these columns separately, and made the code get the vote tally initially on load, use a read_uncommitted connection, send the vote update off on a separate thread, and instead of re-querying for the tally, simply increment the on-load tally by 1 locally.
Net effect: wait-time for voting at 500 users reduced from ~15s to ~240ms, database reads for votes reduced by a factor of 2, expected performance for 1,000,000,000 users: ~630ms*2
So a little planning and application of basic algebraic principles can make the difference between handling a billion users comfortably and reaching a performance limit at 500 users.No doubt, YouTube was in the middle of making a change somewhat along this vein to their voting algorithm when I stumbled onto this bizarre result. I have, in any case, been unable to reproduce it since.
*1 - One might ask why this is a mistake. The reason is that non-technical users don't usually have practice visualizing a complete site from specifications, or being aware of the interdependence between logically separate presentation elements unless specifically shown. What happens then is that when users are shown partial implementations, it sets their wheels turning about the functionality that will go on top of the current functionality, and without looking at the current spec, they will at worst fall into the trap of reinventing already-specified functionality, and at best think of brand new functionality to add, sometimes resulting in significantly increased scope, regressions, and project slippages.
*2 - The performance prediction is based on the number of seeks it requires to read a b-tree index. Updating or inserting a row in a database will require two additional seeks, so we can add 2 to the result, but what is of interest here is noting that this number can be computed pretty reliably using the formula:
log(row_count) / log(index_block_length / 3 * 2 / (index_length + data_pointer_length)) + 1
since block-lengths are usually 1024 bytes, an index on a mediumint column is three bytes long, a data pointer able to hold 4G discrete values is 4 bytes, then for 500 rows:
log(500) / log(1024 / 3 * 2 / (3 + 4)) + 1 = ln(500)/ln(2048/21) + 1 = 2.35
-a write requires 2 additional seek requests. So if we take the complete operation on a 500 row table to require 6.7 seeks (2.35 for the original read and 4.35 for the update), then the same operation on a 1 billion row table will require ~7.8 seeks, and 9.8 for the update, for a total of 17.6.
If 6.7 seeks took ~240ms, 17.6 will take 17.6/6.7*240=630ms
QED
Tuesday, April 16, 2013

Subscribe to:
Posts (Atom)